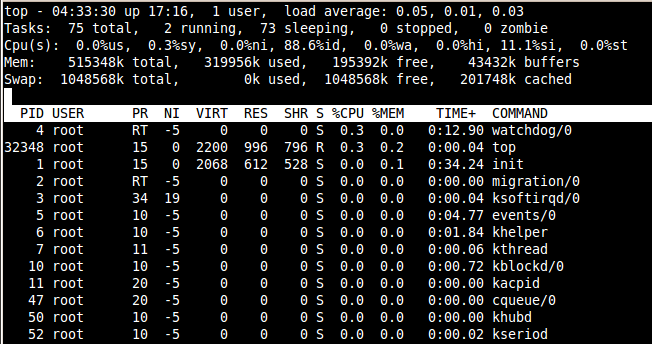
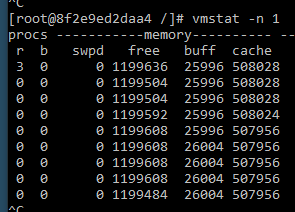
What’s the uptime I can promise my customers? Are there any single points of failure? It may be a complicated question when you have many different components, and each has its probability of shutting down. On that note, you also need to ask yourself if you have proper fail-over procedures and an alert system.
We should also ask ourselves, how do we provide an SLA(service level agreement) when using external resources? Especially when the SLA is not dependent on us but on another company’s product which we have no control of:
- We should never stop serving customers solely because 1 of our external providers collapsed, should provider X crash down or return a delayed response, how will it affect your application?
- Don’t ever be dependent on a single external resource, also make sure you have 2–3 more resources providing the same type of service but don’t overdo it. The trade-off is merging more pieces of data and trust me. It’s not simple.
- Use timeouts and consider wrapping the logical component, which sends the requests, with a circuit breaker. There is nothing worse than a slow response, even one which, eventually, returns a proper result.
- Pessimist Development
Yeah, sounds pretty dire, but we should always assume the worse case, and it doesn’t have to be on our account, especially in the open-source world where we live. Check out some stability & capacity patterns that may help you confine errors to certain parts of your application instead of crashing down the entire system. Release it By Michael T. Nygard extrapolate on these matters pretty well, and I highly recommend you to read it, worth every penny.